论文解读:对端到端语音识别网络的两种全新探索
原标题:论文解读:对端到端语音识别网络的两种全新探索
雷锋网 AI 科技评论按:语音识别技术历史悠久,早在上世纪 50 年代,贝尔研究所就研究出了可以识别十个英文数字的简单系统。从上世纪 70 年代起,传统的基于统计的 HMM 声学模型,N 元组语言模型的发明,已经使得语音识别技术可以在小规模词汇量上使用。在新世纪伊始,GMM-HMM 模型的序列鉴别性训练方法的提出又进一步提升了语音识别的准确率。最近 5-10 年间,随着深度学习的快速发展,算力的快速增长,数据量的急速扩张,深度学习开始大规模应用于语音识别领域并取得突破性进展,深度模型已经可以在干净标准的独白类音频上达到 5% 以下的错词率。此外,端到端的模型可以轻松的将各种语言揉合在一个模型中,不需要做额外的音素词典的准备,这将大大推动业界技术研究与应用落地的进度。
在现在主流的利用深度学习的语音识别模型中仍在存在多种派系,一种是利用深度学习模型取代原来的 GMM 部分,即 DNN-HMM 类的模型,另一种则是端到端的深度学习模型。
第一种模型需要先实现 HMM 结构与语音的对齐,然后才能进一步地训练深度神经网络。除此之外,在训练这一类的模型时,训练样本的标注不仅仅是原本的文本,还需要对文本进一步拆解成为音素投入训练,这对于标注部分的工作就会造成极大的挑战。在解码的时候,这种模型同样还需要依赖这个发音词典。
端到端的模型旨在一步直接实现语音的输入与解码识别,从而不需要繁杂的对齐工作与发音词典制作工作,具有了可以节省大量的前期准备时间的优势,真正的做到数据拿来就可用。
端到端的模型的另一个优点是,更换识别语言体系时可以利用相同的框架结构直接训练。例如同样的网络结构可以训练包含 26 个字符的英文模型,也可以训练包含 3000 个常用汉字的中文模型,甚至可以将中英文的词典直接合在一起,训练一个混合模型。
此外,最重要的一点是,端到端的模型在预测时的速度更快,对于一个 10 秒左右的音频文件,端到端的模型在一块 GPU 的服务器上仅需 0.2 秒左右的时间便可给出预测结果。
现在的语音识别问题有如下几个难点:
对自然语言的识别和理解;
语音信息量大。语音模式不仅对不同的说话人不同,对同一说话人也是不同的,一个说话人在随意说话和认真说话时的语音信息是不同的;
语音的模糊性。说话者在讲话时,不同的词可能听起来是相似的;
单个字母或词、字的语音特性受上下文的影响,以致改变了重音、音调、音量和发音速度等。
端到端的模型由于不引入传统的音素或词的概念,直接训练音频到文本的模型,可以有效地规避上述难点。
云从科技基于端到端的语音识别网络进行了两种方法的探索,一种是基于原有的 CNN-RNN-CTC 网络的改进,一种是基于 CTC loss 与 attention loss 结合机制的网络。下面是对这两种方法的详细解读。
第一种方法
地址:
作者基于百度之前提出的 Deep Speech 2 的模型框架结构,提出了三个改进的点。
第一是把循环神经网络中的长短时记忆层(LSTM)变成了双向的残差长短时记忆层(resBiLSTM)。此举可以更好地保留之前卷积神经网络所提取出的音素信息和之后每一个双向的残差长短时记忆层更好的结合。因为循环神经网络中的每一层主要是负责提取句子中的语义信息,但语义信息的理解也和音素信息紧密相关。随着循环神经网络的深入,原本更底层的层很难接收到卷积神经网络所给出的信息,对于复杂的长句子中音素和语义信息的结合较差,新提出的残差网络可以较好地修正这一问题。
第二点是引入了级联的训练结构,即对于第一个网络中难分(分错)的样本进行二次训练。在实验中我们发现,在第一层网络结构中被分错的样本比全部的样本的平均句长多出了 11% 以上。随着句子的变长,强语法和语义相关的单词会距离更远,那么对于较浅的循环神经网络来说就会更难捕捉到这一个信息。在发现这一区别后,作者在在第二层的级联结构中使用了更深的循环神经网络 (7 层到 13 层),但同时缩减了每一层的隐含节点数(对应样本量的减少,防止出现复杂模型的过拟合问题)。下图是对这两点改进后具体的模型图。
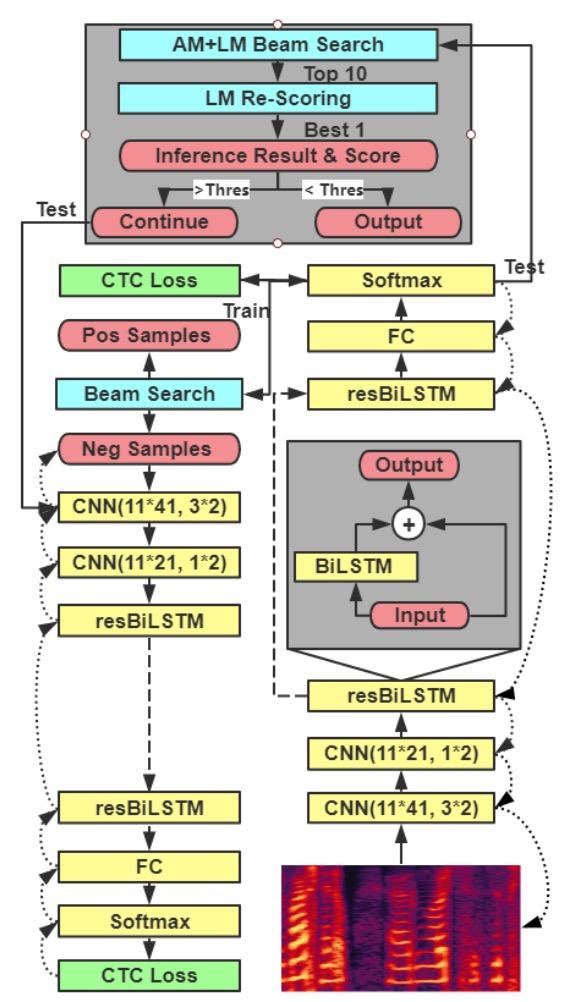
最后一点,是作者提出了新的训练方式来提升训练速度。深度学习中的模型一般都会采用随机梯度下降的方式来训练,每一次只训练其实其中一批数据(mini batch)。原来的训练模式是固定批量的大小从一而终。但是对于语音识别这样的问题来说,输入的数据是不定长的,这就会导致训练时,每一批和每一批的数据中最长的那一条是不一样的。为了防止训练时内存溢出,固定批量的方式必然需要迁就数据集中最长的那一个音频。在我们的训练数据集中,最长的音频是最短的音频的 10 倍左右,这样就会带来在训练短音频时的内存浪费。作者提出一种对全部训练集从低到高排序的方式,每次取排序后的一批音频,之后根据批次内最长的音频片段来实时调整批量的大小,从而提升内存利用率并使得训练时间下降了约 25%。在 LibriSpeech 960 小时的训练数据集上,利用在 8 块 1080Ti 上训练一次的时间从 24500 秒降到 18400 秒左右,减少 25%。且此方法并未因排序失去数据选取的随机性而显得效果变差。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/758.html


